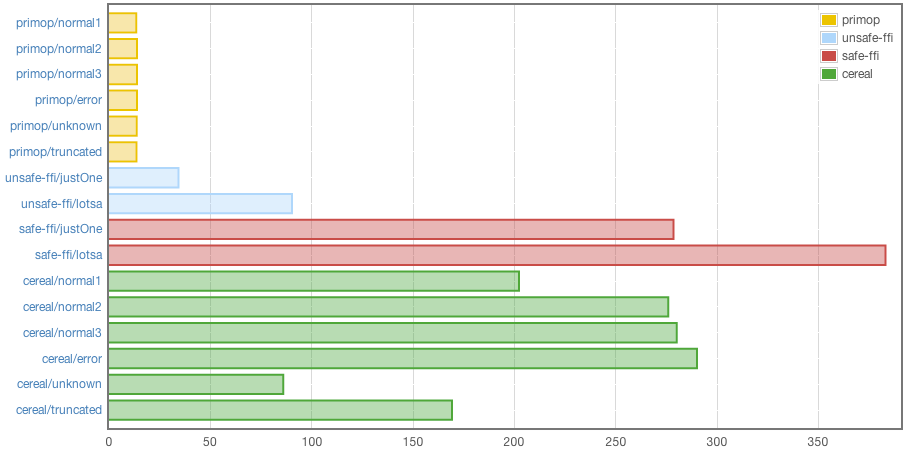
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
| {"author":""
,"bugReports":"http://hackage.haskell.org/trac/ghc/newticket?component=libraries%20%28other%29"
,"buildDepends":[["rts",{"AnyVersion":[]}]]
,"buildType":{"Custom":[]}
,"category":""
,"copyright":""
,"customFieldsPD":[]
,"dataDir":""
,"dataFiles":[]
,"description":"GHC primitives."
,"executables":[]
,"extraSrcFiles":[]
,"extraTmpFiles":[]
,"homepage":""
,"library":
{"exposedModules":
[["GHC","Classes"]
,["GHC","CString"]
,["GHC","Debug"]
,["GHC","Generics"]
,["GHC","Magic"]
,["GHC","PrimopWrappers"]
,["GHC","IntWord64"]
,["GHC","Tuple"]
,["GHC","Types"]
,["GHC","Prim"]]
,"libBuildInfo":
{"buildTools":[]
,"buildable":true
,"cSources":["cbits/debug.c","cbits/longlong.c","cbits/popcnt.c"]
,"ccOptions":[]
,"cppOptions":[]
,"customFieldsBI":[]
,"defaultExtensions":[]
,"defaultLanguage":null
,"extraLibDirs":[]
,"extraLibs":[]
,"frameworks":[]
,"ghcProfOptions":[]
,"ghcSharedOptions":[]
,"hsSourceDirs":["."]
,"includeDirs":[]
,"includes":[]
,"installIncludes":[]
,"ldOptions":[]
,"oldExtensions":
[{"EnableExtension":{"CPP":[]}}
,{"EnableExtension":{"MagicHash":[]}}
,{"EnableExtension":{"ForeignFunctionInterface":[]}}
,{"EnableExtension":{"UnliftedFFITypes":[]}}
,{"EnableExtension":{"UnboxedTuples":[]}}
,{"EnableExtension":{"EmptyDataDecls":[]}}
,{"DisableExtension":{"ImplicitPrelude":[]}}]
,"options":[[{"GHC":[]},["-package-name","ghc-prim"]]]
,"otherExtensions":[]
,"otherLanguages":[]
,"otherModules":[]
,"pkgconfigDepends":[]
,"targetBuildDepends":[]}
,"libExposed":true}
,"license":{"BSD3":[]}
,"licenseFile":"LICENSE"
,"maintainer":"libraries@haskell.org"
,"package":{"pkgName":"ghc-prim","pkgVersion":{"versionBranch":[0,2,0,0],"versionTags":[]}}
,"pkgUrl":""
,"sourceRepos":
[{"repoBranch":null
,"repoKind":{"RepoHead":[]}
,"repoLocation":"http://darcs.haskell.org/packages/ghc-prim.git/"
,"repoModule":null
,"repoSubdir":null
,"repoTag":null
,"repoType":{"Git":[]}}]
,"specVersionRaw":
{"Right":
{"UnionVersionRanges":
[{"ThisVersion":{"versionBranch":[1,6] ,"versionTags":[]}},
{"LaterVersion":{"versionBranch":[1,6],"versionTags":[]}}]}}
,"stability":""
,"synopsis":"GHC primitives"
,"testSuites":[]
,"testedWith":[]}
|